Using tiny forked VMs to accelerate compute functions (for personal projects)
Chasing more performance can be fun to do, but it can also be very hard. It is a fact that my RISC-V emulator has particular choices built into it that complicates many directions I could go in search of better performance. Also, I have no intention of implementing something like JIT right now, or use anonymous mappings (with CoW zero pages) to simplify memory. Quite frankly, there are a lot of things I could do, but it’s a hobby project, and I also like the idea of it being embeddable anywhere. Secondly, this feature is primarily for myself: I am using the RISC-V emulator in a game engine as a scripting backend. Really quite fun to work with, actually.
The RISC-V emulator is itself a highly embeddable library using CMake options to enable and disable features. It is built with a page table-based memory where pages have data and permissions, including copy-on-write mechanisms. You can also take pages from one machine and loan out to another. Or install your own pages temporarily, or decide what happens when you make pages writable, or if you read or write to a page that’s not there. All of this combined give you the ability to hand-craft weird things like remote machine-to-machine function calls. Sadly, it also makes it really really hard to add multiprocessing or any kind of concurrency to it.
Multiprocessing
With multiprocessing the goal is to execute with more than one CPU on the shared memory in the machine and perform tasks faster than previously by splitting them up. Since the CPUs aren’t real we will just call them virtual CPUs or vCPUs for short.
One way to implement it would be to have a machine with more than one CPU and a single memory. Any time we would make page table changes we would have to use a lock, and we would have to make sure each vCPU saw the memory the same way, after the change. On real hardware, this is made possible using highly complex network-protocol-like transmissions between CPUs to make memory and page tables coherent, as well as invalidating outdated cache entries. Additionally, there are lots of complicated circuitry to deal with atomic operations. Fun fact: Reads are largely atomic, as long as alignment of the operation is kept. Even AVX512 loads and stores can be atomic 64-byte reads and writes! Real hardware is in many ways amazing.
Method
I had an idea that I would start with just a simple feature: A system function that creates N vCPUs, and each of them call the same function with differing CPU IDs. Enough to implement simple compute kernels.
multiprocess(4, work_function, &work_data);
multiprocess_wait();Would start 4 extra vCPUs, and then you would call the wait function before reading the results. multiprocess_wait needs to be an extern function call in the guest, so that memory becomes clobbered to the compiler. The feature can work like an async task that you wait for once you have done other work. It is also not mandated that you wait, so perhaps you can start and forget? The only drawback right now is that you can only have one operation going at a time. There is no way to wait for a specific task to finish without keeping futures. Perhaps we can use a map that ties a task id to a list of futures, and that would be something to expand the API with if I ever end up needing it.
Multiprocessing v1
After implementing multiprocessing the first time, the performance was so bad that it could not be used for anything. But it worked. I had to implement CPU-local caches to avoid as many locks as possible etc. In short, the memory subsystem was not able to communicate with the vCPUs how pages changed, without stopping the world. The implementation made it possible to have more than one CPU executing on the same machine, but the way it was designed did not lend itself well to it. I also didn’t really see a solution to the problems I had even if I had started bigger rewrites. It simply was the wrong way to go if I wanted to have a chance at unimpeded multiprocessing.
To measure the multiprocessing performance I benchmarked a dot-product function. The function takes two arrays of 8192 fp32 values, multiplying one float from array A with the same index in B, and adds it to a sum. The final sum is the dot product:
fp32 sum = 0.0f
sum += a[i] * b[i]
return sumThis function could instead take a portion of the whole work, and write a partial sum by using the CPU ID as index as the result. At the end we can sum the partial sums to get the final dot product. Simple compute stuff. To verify, we can set each fp32 value to 1.0, and the dot-product will be the number of elements in the arrays.
The multiprocessing performance ended up being way worse than the singleprocessing performance. It actually made me really miffed, and I felt like the emulator was missing out on a big feature because it was designed differently.
Multiprocessing v2
As luck would have it, the emulator supports really really fast forking of machines already. A feature I use professionally, for undisclosed things. One of the benefits of being able to create new machines in about a microsecond, on average, is that if nothing else I could uselessly compute parts of the compute kernel on each machine. And then perhaps collect it at the end.
But, it turned out to be much simpler than that. See, compute kernels often have the data readily available, and iterates over it, writing out new data. So, let’s start with a threadpool that enqueues lambdas as work. In each lambda we create a fork of the main VM, then we do all the setup necessary to execute the right function. When a vCPU worker has finished forking the main VM, it will immediately execute the work function. The main VM waits until everyone has forked until it resumes its own execution.
It would not be possible to communicate which part of the work we needed and only fork selected parts of the main VM. Compiled languages have data all over the place. While it is possible to define the work as a list of memory arrays that we could use to minimize the forking time, it is probably less painful for everyone to just fork the main VM. For the peace of mind that at least it’s not failing because there was a random hole in the memory.
We also hook up a write function that makes it so that writes to copy-on-write pages cause the page to be created on the main VM and then loaned out to the other VM. All of this under a lock. The result is that everyone can contribute memory writes to the result.
Example API usage
struct { ... } mp_work;// Start 4 vCPUs and run the given function
multiprocess(4, multiprocessing_function, &mp_work);
// Perform some other work...
other_work();
// Wait for all multiprocessing to end
multiprocess_wait();
Multiprocessing v3
In order to make the API more flexible, we will make it more like a fork/clone system call. Instead of passing a function and a data argument, we just make every vCPU return from the multiprocessing system call with a different return value. And, we can also use the mhartid CSR to get the unique ID of the vCPU:
uint64_t id;
asm ("csrr %0, mhartid\n" : "=r"(id));
return id;Using this we have a function that acts like true multi-processing, and it can help us support other things like multiprocessing threads, in the future.
The stack is copy-on-write, so we do have the original stack frames and everything, but sadly we cannot use them. The reason is that when we write to a CoW page, we want that page to reside in the main machine, and as a result, the machines would trample on each others stacks. Stacks have no meaningful boundaries in any runtime that I know of, which makes the most beautiful solution impossible: Sharing the main stack with everyone, but making it copy-on-write such that we do not need to hand-write the system call handling in assembly. That is not the way things are, so we will just have to go with the lesser version. In this example the system call number for multiprocessing is 110, and ecall is the instruction that triggers it.
extern "C" long sys_multiprocess(unsigned, void*, size_t, mp_func_t, void*);
extern "C" long sys_multiprocess_wait();static struct {
uint64_t* stacks = nullptr;
unsigned cpus = 0;
} mp_data;unsigned multiprocess(unsigned cpus, mp_func_t func, void* data)
{
constexpr size_t STACK_SIZE = 512 * 1024u;
if (mp_data.cpus < cpus) {
mp_data.cpus = cpus;
delete[] mp_data.stacks;
mp_data.stacks = new uint64_t[(STACK_SIZE * cpus) / 8];
}
return sys_multiprocess(cpus, mp_data.stacks, STACK_SIZE, func, data);
}asm(".global sys_multiprocess\n"
"sys_multiprocess:\n"
" li a7, 110\n"
" ecall\n"
" beqz a0, sys_multiprocess_ret\n" // Early return for vCPU 0
// Otherwise, create a function call
" addi a0, a0, -1\n" // Subtract 1 from vCPU ID, making it 0..N-1
" mv a1, a4\n" // Move work data to argument 1
" jalr zero, a3\n" // Direct jump to work function
"sys_multiprocess_ret:\n"
" ret\n"); // Return to caller
This lets us use a simpler system call API that only takes the number of worker vCPUs, the stack base and stack size. The system call returns the currently running CPU ID (hart thread id in RISC-V lingo), and with that we can choose what to do: With vCPU = 0 we just return, and for all the workers we call the function with CPU ID 0..N-1 and the data argument, just like before. The direct jump makes it so that when we return from the work function, we will actually return to whoever called sys_multiprocess. Efficiency!
Multiprocessing v4
Since I am in full control of my environment, including the threading implementation, I started recording the stack base addresses and size. Using that I introduced a second approach to multiprocessing where we pass the stack boundaries to the write fault handler, and with that we can actually sit on the current stack safely, and avoid having to write any assembly other than to execute the system call. Since everything remains the same after the system call, it would be possible to inline it too, and only clobber the return value which gives you the vCPU ID. The drawback is that the stack is no longer shared between the vCPUs, and that can cause surprises to programmers. For this reason we make available both methods. It is more natural to start a new thread using a new carefully crafted stack anyway.
This version is slightly faster than v3, due to the fact that we _have_ to immediately wait for all the workers on vCPU 0 after forking. This is because we have to avoid trampling the stack for all the workers who rely on it using copy-on-write mechanics. This method is around 1 microsecond faster than the graph is showing below, finishing in 36 microseconds, as I never updated the chart. This is what using the API looks like for this method:
unsigned cpu = multiprocess(4);
if (cpu != 0) {
multiprocessing_function (cpu-1, &mp_work);
// Stop multiprocessing here
multiprocess_wait();
}Can you do this using a regular glibc program?I believe that you can. Using pthread_self() and pthread_attr_getstack() you can get the stack boundaries before you make the multiprocess system call. It is natural to insert your own system calls with libriscv, and if you are hosting glibc guest programs, you could design your own multiprocess system call to take stack base and size as arguments.
Results
Measuring the final versions leaves us with 6 different benchmarks. First, the normal naive version where we calculate the dot product on a single thread, and then we follow up with 4x multiprocessing. Finally, with binary translation also enabled.
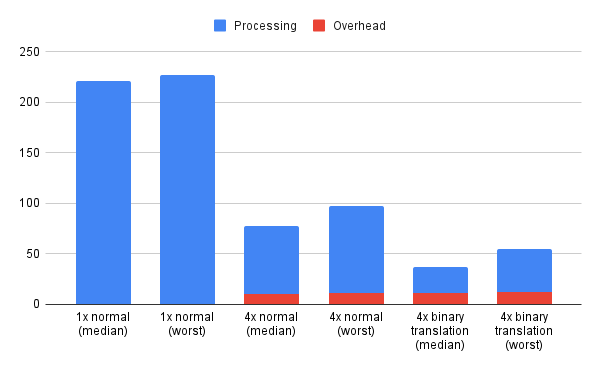
The results were pretty decent. With 4 threads in total I was able to cut the processing time of the dot product in three. And with my puny binary translation that I wrote about before, it was halved again: Starting at 210 micros, and down to around 37 micros. In the end a mere 16% runtime compared to the initial case. Without binary translation the multiprocessing version completed in 78 microseconds on average, and was 35% of the normal runtime. And last, the overhead of 4x multiprocessing tasks was a whopping 11 microseconds! That, hopefully, can be improved upon.
-gonzo